
Performing basic NLP using spaCy (PY)
In my previous post, we used a crypto news database scraped from Reuters to perform LDA topic modelling. This time, I will present an overview of spaCy, one of the most important Natural Language Processing (NLP) libraries for Python. The objective of this post is to do the following:
- Perform basic NLP using spaCy on a news title
- Redo this exercise with one article
- Apply a spaCy pipeline to process the entire news data set
Part 1: Performing basic NLP using spaCy with one news title
When I started researching NLP for my previous consultancy, it was useful to take small steps. NLP is a massive field and it was difficult knowing where to start. Thankfully, spaCy is quite friendly to beginners. So let’s start with something simple and perform basic NLP for one news title. First, we will load some required libraries and the crypto data sample.
#importing the required packages:
import pandas as pd
import spacy
from IPython.display import SVG
#loading the crypto database:
df = pd.read_csv("crypto_sample.csv")
#checking the first news articles of the dataset:
df.head(5)
| Publication Date | Title | Decription | Text | URL |
|---|---|---|---|---|
| 2021-03-29T08:54:19Z | Exclusive: Visa moves to allow payment settlem... | Visa Inc said on Monday it will allow the use ... | (Reuters) - Visa Inc said on Monday it will al... | https://www.reuters.com/article/us-crypto-curr... |
| 2021-03-30T09:34:52Z | Exclusive: PayPal launches crypto checkout ser... | PayPal Holdings Inc will announce later on Tue... | LONDON (Reuters) - PayPal Holdings Inc will an... | https://www.reuters.com/article/us-crypto-curr... |
| 2021-03-14T23:39:06Z | India to propose cryptocurrency ban, penalisin... | India will propose a law banning cryptocurrenc... | NEW DELHI/MUMBAI (Reuters) - India will propos... | https://www.reuters.com/article/uk-india-crypt... |
| 2021-04-05T16:36:21Z | Crypto market cap surges to record $2 trillion... | The cryptocurrency market capitalization hit a... | NEW YORK (Reuters) - The cryptocurrency market... | https://www.reuters.com/article/us-crypto-curr... |
| 2021-03-29T08:45:40Z | EXCLUSIVE-Visa moves to allow payment settleme... | Visa Inc said on Monday it will allow the use ... | March 29 (Reuters) - Visa Inc said on Monday i... | https://www.reuters.com/article/crypto-currenc... |
Now we will subset the title from the third article, which seems quite interesting. Then, we’ll load the spaCy nlp function using the default English model. If we wanted to perform NLP in another language, there are plenty of other models to choose from:
#subsetting the third news article:
title3 = df["Title"][2]
#loading the nlp function using the english model:
nlp = spacy.load("en_core_web_sm")
#applying this function and creating a spacy object called t3:
t3 = nlp(title3)
Now that we have this spaCy object, we will check some of its attributes:
#to view the actual text of the doc:
t3.text
'India to propose cryptocurrency ban, penalising miners, traders - source'
#to see the sentiment score, if available:
t3.sentiment
0.0
Next, we can proceed to use spaCy’s NER to see which entities (people, places, names, etc.) are identified in this news title:
#to view the names of the entities identified in the doc:
t3.ents
(India,)
In order to see how spaCy is categorizing this entity we do the following:
#show NER with labels:
[(ent, ent.label_) for ent in t3.ents]
[(India, 'GPE')]
The GPE corresponds to the category “Country, cities, states”. It’s a bit difficult finding a complete list of the entities covered in spaCy, but this thread offers various solutions. Next, we will try the Part of Speech (POS) tagger, which enables spaCy to make predictions on which tag most likely applies to a word. For example, the is most likely a noun in English:
#Now we will try the POS tagger:
tokens = list()
for token in t3:
tokens.append((token.text, token.lemma_, token.tag_, token.pos_))
#making a df to visualize this better:
pd.DataFrame(tokens, columns=['Text', 'Lemma','Short POS','POS'])
| Text | Lemma | Short POS | POS |
|---|---|---|---|
| India | India | NNP | PROPN |
| to | to | TO | PART |
| propose | propose | VB | VERB |
| cryptocurrency | cryptocurrency | NN | NOUN |
| ban | ban | NN | NOUN |
| , | , | , | PUNCT |
| penalising | penalise | VBG | VERB |
| miners | miner | NNS | NOUN |
| , | , | , | PUNCT |
| traders | trader | NNS | NOUN |
| - | - | HYPH | PUNCT |
| source | source | NN | NOUN |
The model is able to identify punctuation, proper nouns like India, and verbs such as penalising with its respective lemma or cannonical form. If this impressed you, the next step is really fascinating:
#let's try the dependency parser and save the resulting image:
from spacy import displacy
from pathlib import Path
#extra customization for the displacy plot:
options = {"compact": True, "bg": "midnightblue",
"color": "white", "font": "Georgia"}
#making the displacy plot and storing it as svg:
svg = displacy.render(t3, style="dep", options=options, jupyter=False)
#saving the output in my working directory:
output_path = Path("india.svg")
output_path.open("w", encoding="utf-8").write(svg)
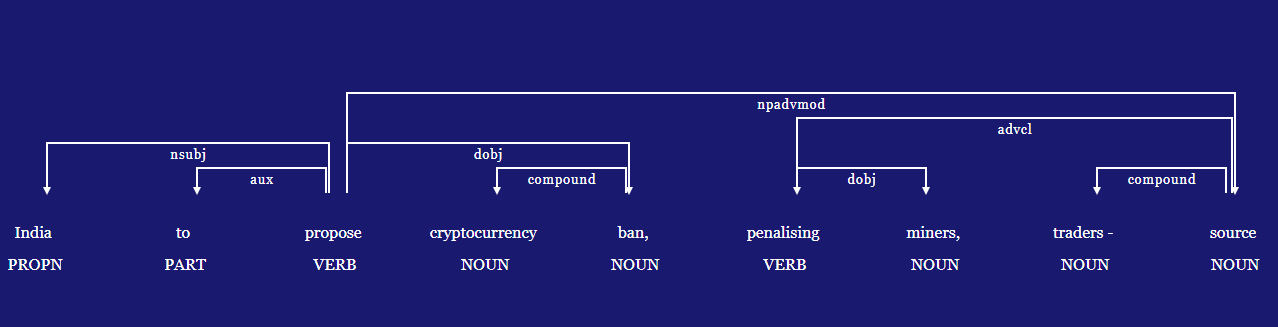
Really interesting, right? The displacy plot showcases the dependencies in this sentence. If we wanted to inspect what specific abbreviations mean we can do the following:
spacy.explain('npadvmod'), spacy.explain('dobj'), spacy.explain('advcl'), spacy.explain('nsubj')
('noun phrase as adverbial modifier',
'direct object',
'adverbial clause modifier',
'nominal subject')
This information becomes crucial when building custom rule based matchers.
Part 2: Redoing this exercise for one article
Now that we have some basics down, it’s time to apply this to an entire article. This time, I will not go into much detail explaining the code, as the logic is quite similar. First, we will make a spaCy object of the third news article and perform similar NLP tasks:
#subsetting the third news article:
article3 = df["Text"][2]
#loading the nlp function using the english model:
nlp = spacy.load("en_core_web_sm")
#applying this function and creating a spacy object called art3:
art3 = nlp(article3)
#making a list of the entities and their labels:
l3 = [(ent, ent.label_) for ent in art3.ents]
#viewing the first five elements of the list:
l3[0:5]
[(NEW DELHI/MUMBAI, 'GPE'),
(India, 'GPE'),
(Reuters, 'ORG'),
(millions, 'CARDINAL'),
(one, 'CARDINAL')]
The same procedure can be applied to the POS tagging. In this case, we just want to view the first 10 tags of the news article:
#Now we will try the POS tagger:
tokens = list()
for token in art3:
tokens.append((token.text, token.lemma_, token.tag_, token.pos_))
#making a df to visualize this better:
df2 = pd.DataFrame(tokens, columns=['Text', 'Lemma','Short POS','POS'])
df2.head(10)
| Text | Lemma | Short POS | POS |
|---|---|---|---|
| NEW | NEW | NNP | PROPN |
| DELHI | DELHI | NNP | PROPN |
| / | / | SYM | SYM |
| MUMBAI | MUMBAI | NNP | PROPN |
| ( | ( | -LRB- | PUNCT |
| Reuters | Reuters | NNP | PROPN |
| ) | ) | -RRB- | PUNCT |
| - | - | : | PUNCT |
| India | India | NNP | PROPN |
| will | will | MD | AUX |
Note how the Text label corresponds to the the token.text element in the for loop. When using the nlp function, spaCy automatically divides the text into tokens, including words and punctuations. This is very useful, for example, if we want to find the most commonly used words in this article. In the following chunk of code, we will perform this word count, while also removing stopwords using another spaCy function:
from collections import Counter
#adding line breaks as a stopword:
nlp.Defaults.stop_words.add("\n\n")
#reloading the nlp function using the english model:
nlp = spacy.load("en_core_web_sm")
#applying this function and creating a spacy object called art3:
art3 = nlp(article3)
#remove stopwords and punctuations:
words = [token.text
for token in art3
if not token.is_stop and not token.is_punct]
#measuring word frequency using the Counter function:
word_freq = Counter(words)
#checking the five most common words:
common_words = word_freq.most_common(5)
#printing the most common words:
print (common_words)
[('official', 10), ('government', 9), ('said', 9), ('ban', 7), ('India', 6)]
This gives us a better idea of what this article is about! Now can finish with another nice visualization for the first 200 words of the article. The output should look something like this:
SVG(data = displacy.render(art3[0:200], style="ent"))

Now we can really appreciate how spacy is “reading” the article and applying the NER tags! Let’s take things one step further and process the entire database…
Part 3: Applying a spacy pipeline to process the entire data set
Now comes the crucial part: applying these techniques to an entire dataset. One possibility would be to create a loop to iterate through each article in the dataframe with the nlp function. The most efficient approach however, is to take advantage of spacy’s pipleline. For now, let’s inspect the default components in the pipeline:
print(nlp.pipe_names)
['tok2vec', 'tagger', 'parser', 'ner', 'attribute_ruler', 'lemmatizer']
We can see the different components available, including the POS tagger and NER. For now, will use a fastprogress bar to check the performance of the pipe:
import fastprogress
#checking the performance of the pipe:
docs = list(fastprogress.progress_bar(nlp.pipe((df['Text'])),total=len(df)))
The pipe took 17 seconds to process all the articles! Let’s double check if it worked using the same article as before:
#printing the entities for the third article just to be sure the pipe worked:
print([(ent, ent.label_) for ent in docs[2].ents])
[(NEW DELHI/MUMBAI, 'GPE'), (India, 'GPE'), (Reuters, 'ORG'), (millions, 'CARDINAL'), (one, 'CARDINAL'), (January, 'DATE'), (up to six months, 'DATE'), (Narendra Modi, 'PERSON'), (India, 'GPE'), (first, 'ORDINAL'), (China, 'GPE'), (The Finance Ministry, 'ORG'), (60,000, 'MONEY'), (Saturday, 'DATE'), (this year, 'DATE'), (Tesla Inc, 'ORG'), (Elon Musk, 'PERSON'), (India, 'GPE'), (8 million, 'CARDINAL'), (100 billion, 'MONEY'), ($1.4 billion, 'MONEY'), (every month, 'DATE'), (Sumnesh Salodkar, 'PERSON'), (Bitbns, 'GPE'), (30-fold, 'CARDINAL'), (a year ago, 'DATE'), (Gaurav Dahake, 'ORG'), (Unocoin, 'ORG'), (one, 'CARDINAL'), (India, 'GPE'), (20,000, 'CARDINAL'), (January, 'DATE'), (February, 'DATE'), (February 2021, 'DATE'), (February 2020, 'DATE'), (Vikram Rangala, 'PERSON'), (Indian, 'NORP'), (Finance, 'ORG'), (Nirmala Sitharaman, 'PERSON'), (this month, 'DATE'), (CNBC, 'ORG'), (Reuters, 'ORG'), (2019, 'DATE'), (up to 10 years, 'DATE'), (March 2020, 'DATE'), (India, 'GPE'), (Supreme Court, 'ORG'), (2018, 'DATE'), (The Reserve Bank of India, 'ORG'), (last month, 'DATE'), (Naimish Sanghvi, 'PERSON'), (the last year, 'DATE'), (Reuters, 'ORG')]
Let’s contrast this with the loop approach, using tqdm to measure the loop performance:
from tqdm import tqdm
docs2 = []
for i in tqdm(range(len(df))):
d = nlp(df['Text'][i])
docs2.append(d)
len(docs2)
100%|████████████████████████████████████████████████████████████████████████████████| 146/146 [00:20<00:00, 6.96it/s]
We can see the loop approach took aproximately 3 seconds longer than the pipe. This difference becomes much more significant once we work with larger datasets. Either way, now we can extract the same information for all the articles. Let’s start with making a simple loop to generate a list with the entities for each article:
NER = []
for i in range(len(docs)):
e = [(ent, ent.label_) for ent in docs[i].ents]
NER.append(e)
len(NER)
146
Next, we can extract only the proper nouns (PN) from the document using another loop. This time we will use a conditional if statement, to retreive only those tokens with the the POS tag “PROPN”.
#remove stopwords and punctuations:
PN = []
for i in range(len(docs)):
pos = [token.text
for token in docs[i]
if token.pos_ == "PROPN"]
PN.append(pos)
len(PN)
146
Lastly, let’s see what are the five most common words (TW) for each article, using a similar loop:
#remove stopwords and punctuations:
TW = []
for i in range(len(docs)):
words = [token.text
for token in docs[i]
if not token.is_stop and not token.is_punct]
word_freq = Counter(words)
common_words = word_freq.most_common(5)
TW.append(common_words)
len(TW)
146
Now, let’s put all of this together in a dataframe. Clearly, there could be even more processing done to each list generated per article. However, this seems like a good place to stop for now:
#exporting the second df:
import numpy
import pandas as pd
dict = {'Article': df['Text'], 'NER entities' : NER, 'Proper nouns': PN, 'Most common words': TW}
#making df2:
df1 = pd.DataFrame(dict)
#checking:
df1.head()
| Article | NER entities | Proper nouns | Most common words |
|---|---|---|---|
| (Reuters) - Visa Inc said on Monday it will al... | [((Reuters), ORG), ((Visa, Inc), ORG), ((Monda... | [Reuters, Visa, Inc, Monday, USD, Coin, Reuter... | [(Visa, 8), (use, 6), (digital, 6), (Inc, 4), ... |
| LONDON (Reuters) - PayPal Holdings Inc will an... | [((LONDON), GPE), ((Reuters), ORG), ((PayPal, ... | [LONDON, Reuters, PayPal, Holdings, Inc, Tuesd... | [(PayPal, 9), (said, 6), (merchants, 5), (hold... |
| NEW DELHI/MUMBAI (Reuters) - India will propos... | [((NEW, DELHI, /, MUMBAI), GPE), ((India), GPE... | [NEW, DELHI, MUMBAI, Reuters, India, Reuters, ... | [(official, 10), (government, 9), (said, 9), (... |
| NEW YORK (Reuters) - The cryptocurrency market... | [((NEW, YORK), GPE), ((Reuters), ORG), (($, 2,... | [NEW, YORK, Reuters, Monday, CoinGecko, Blockf... | [($, 13), (market, 9), (bitcoin, 8), (trillion... |
| March 29 (Reuters) - Visa Inc said on Monday i... | [((March, 29), DATE), ((Reuters), ORG), ((Visa... | [March, Reuters, Visa, Inc, Monday, USD, Coin,... | [(Visa, 9), (digital, 6), (said, 5), (use, 5),... |
Conclusions
I admit this table isn’t pretty, but it shows the complexity of NLP! Generating friendly output in traditional data structures requires more advanced programming. Still, we went from analyzing a single sentence to processing an entire database using spaCy. Hope this is a good starting point for your journey into NLP.